Moving to TruLens v1: Reliable and Modular Logging and Evaluation¶
It has always been our goal to make it easy to build trustworthy LLM applications. Since we launched last May, the package has grown up before our eyes, morphing from a hacked-together addition to an existing project (trulens-explain) to a thriving, agnostic standard for tracking and evaluating LLM apps. Along the way, we’ve experienced growing pains and discovered inefficiencies in the way TruLens was built. We’ve also heard that the reasons people use TruLens today are diverse, and many of its use cases do not require its full footprint.
Today we’re announcing an extensive re-architecture of TruLens that aims to give developers a stable, modular platform for logging and evaluation they can rely on.
Split off trulens-eval from trulens-explain¶
Split off trulens-eval from trulens-explain, and let trulens-eval take over the trulens package name. TruLens-Eval is now renamed to TruLens and sits at the root of the TruLens repo, while TruLens-Explain has been moved to its own repository, and is installable at trulens-explain.
Separate TruLens-Eval into different trulens packages¶
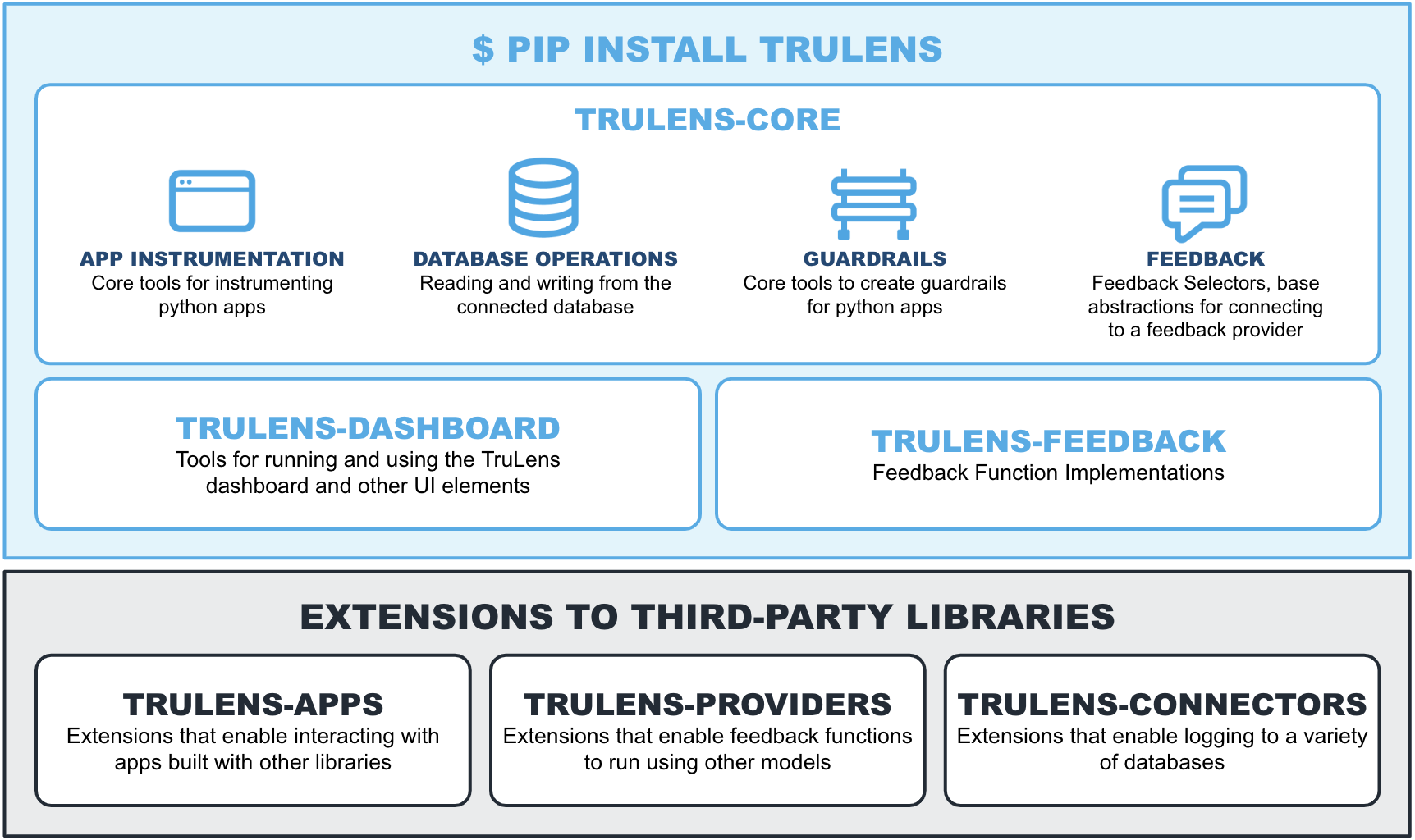
Next, we modularized TruLens into a family of different packages, described below. This change is designed to minimize the overhead required for TruLens developers to use the capabilities they need. For example, you can now install instrumentation packages in production without the additional dependencies required to run the dashboard.
trulens-coreholds core abstractions for database operations, app instrumentation, guardrails and evaluation.trulens-dashboardgives you the required capabilities to run and operate the TruLens dashboard.trulens-apps-prefixed packages give you tools for interacting with LLM apps built with other frameworks, giving you capabilities including tracing, logging and guardrailing. These includetrulens-apps-langchainandtrulens-apps-llamaindexwhich hold our popularTruChainandTruLlamawrappers that seamlessly instrument LangChain and LlamaIndex apps.trulens-feedbackgives you access to out of the box feedback functions required for running feedback functions. Feedback function implementations must be combined with a selected provider integration.trulens-providers-prefixed package describes a set of integrations with other libraries for running feedback functions. Today, we offer an extensive set of integrations that allow you to run feedback functions on top of virtually any LLM. These integrations can be installed as standalone packages, and include:trulens-providers-openai,trulens-providers-huggingface,trulens-providers-litellm,trulens-providers-langchain,trulens-providers-bedrock,trulens-providers-cortex.trulens-connectors-provide ways to log TruLens traces and evaluations to other databases. In addition to connect to anysqlalchemydatabase withtrulens-core, we've added withtrulens-connectors-snowflaketailored specifically to connecting to Snowflake. We plan to add more connectors over time.
Versioning and Backwards Compatibility¶
Today, we’re releasing trulens, trulens-core, trulens-dashboard, trulens-feedback, trulens-providers packages, trulens-connectors packages and trulens-apps packages at v1.0. We will not make breaking changes in the future without bumping the major version.
The base install of trulens will install trulens-core, trulens-feedback and trulens-dashboard making it easy for developers to try TruLens.
Starting 1.0, the trulens_eval package is being deprecated in favor of trulens and several associated required and optional packages.
Until 2024-10-14, backwards compatibility during the warning period is provided by the new content of the trulens_eval package which provides aliases to the in their new locations. See trulens_eval.
Starting 2024-10-15 until 2025-12-01. Usage of trulens_eval will produce errors indicating deprecation.
Beginning 2024-12-01 Installation of the latest version of trulens_eval will be an error itself with a message that trulens_eval is no longer maintained.
Along with this change, we’ve also included a migration guide for moving to TruLens v1.
Please give us feedback on GitHub by creating issues and starting discussions. You can also chime in on slack.
TruLens 1.0 Examples¶
To see the core re-architecture changes in action, we've included some usage examples below:
Log and Instrument LLM Apps
pip install trulens-core
from trulens.apps.app import instrument
class CustomApp:
def __init__(self):
self.retriever = CustomRetriever()
self.llm = CustomLLM()
self.template = CustomTemplate(
"The answer to {question} is {answer}"
)
@instrument()
def retrieve_chunks(self, data):
return self.retriever.retrieve_chunks(data)
@instrument()
def respond_to_query(self, input):
chunks = self.retrieve_chunks(input)
answer = self.llm.generate(",".join(chunks))
output = self.template.fill(question=input, answer=answer)
return output
ca = CustomApp()
pip install trulens-apps-langchain
from langchain import hub
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
from trulens.apps.langchain import TruChain
# Wrap application
tru_recorder = TruChain(
chain,
app_id='Chain1_ChatApplication'
)
# Record application runs
with tru_recorder as recording:
chain("What is langchain?")
pip install trulens-core trulens-apps-llamaindex
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
from trulens.apps.llamaindex import TruLlama
from trulens.core import Feedback
tru_recorder = TruLlama(query_engine,
app_id='LlamaIndex_App1')
with tru_recorder as recording:
query_engine.query("What is LlamaIndex?")
Run Feedback Functions with different LLMs
pip install trulens-core trulens-providers-openai
from trulens.providers.openai import OpenAI
from trulens.core import Feedback
import numpy as np
provider = OpenAI()
# Use feedback
f_context_relevance = (
Feedback(provider.context_relevance_with_context_reasons)
.on_input()
.on(context) # Refers to context defined from `select_context`
.aggregate(np.mean)
)
pip install trulens-core trulens-providers-litellm
from trulens.providers.litellm import LiteLLM
from trulens.core import Feedback
import numpy as np
provider = LiteLLM(
model_engine="ollama/llama3.1:8b", api_base="http://localhost:11434"
)
# Use feedback
f_context_relevance = (
Feedback(provider.context_relevance_with_context_reasons)
.on_input()
.on(context) # Refers to context defined from `select_context`
.aggregate(np.mean)
)
pip install trulens-core trulens-providers-huggingface
from trulens.core import Feedback
from trulens.core import Select
from trulens.providers.huggingface import Huggingface
# Define a remote HuggingFace groundedness feedback function
provider = Huggingface()
f_remote_groundedness = (
Feedback(
provider.groundedness_measure_with_nli,
name="[Remote] Groundedness",
)
.on(Select.RecordCalls.retrieve.rets.collect())
.on_output()
)
Run the TruLens dashboard:
pip install trulens-dashboard
from trulens.core import Tru
from trulens.dashboard import run_dashboard
tru = Tru()
run_dashboard(tru)
TruLens Sessions¶
In TruLens, we have long had the Tru() class, a singleton that sets the logging configuration. Many users and new maintainers have found the purpose and usage of Tru() not as clear as it could be.
In v1, we are renaming Tru to TruSession, to represent a session for logging TruLens traces and evaluations. In addition, we have introduced a more deliberate set of database of connectors that can be passed to TruSession().
You can see how to start a TruLens session logging to a postgres database below:
Start a TruLens Session
from trulens.core import TruSession
from trulens.core.database.connector import DefaultDBConnector
connector = DefaultDBConnector(database_url="postgresql+psycopg://trulensuser:password@localhost/trulens")
session = TruSession(connector=connector)
Note
database_url can also be passed directly to TruSession()
Up-leveled Experiment Tracking¶
In v1, we’re also introducing new ways to track experiments with app_name and app_version. These new required arguments replace app_id to give you a more dynamic way to track app versions.
In our suggested workflow, app_name represents an objective you’re building your LLM app to solve. All apps with the same app_name should be directly comparable with each other. Then app_version can be used to track each experiment. This should be changed each time you change your application configuration. To more explicitly track the changes to individual configurations and semantic names for versions - you can still use app metadata and tags!
Track Experiments
tru_rag = TruApp(
rag,
app_name="RAG",
app_version="v1",
tags="prototype",
metadata=metadata={
"top_k": top_k,
"chunk_size": chunk_size,
}
)
To bring these changes to life, we've also added new filters to the Leaderboard and Evaluations pages. These filters give you the power to focus in on particular apps and versions, or even slice to apps with a specific tag or metadata.
First-class support for Ground Truth Evaluation¶
Along with the high level changes in TruLens v1, ground truth can now be persisted in SQL-compatible datastores and loaded on demand as pandas DataFrame objects in memory as required. By enabling the persistence of ground truth data, you can now easily store and share ground truth data used across your team.
Using Ground Truth Data
import pandas as pd
from trulens.core import TruSession
session = TruSession()
data = {
"query": ["What is Windows 11?", "who is the president?", "what is AI?"],
"query_id": ["1", "2", "3"],
"expected_response": ["greeting", "Joe Biden", "Artificial Intelligence"],
"expected_chunks": [
"Windows 11 is a client operating system",
["Joe Biden is the president of the United States", "Javier Milei is the president of Argentina"],
["AI is the simulation of human intelligence processes by machines", "AI stands for Artificial Intelligence"],
],
}
df = pd.DataFrame(data)
session.add_ground_truth_to_dataset(
dataset_name="test_dataset_new",
ground_truth_df=df,
dataset_metadata={"domain": "Random QA"},
)
from trulens.core import Feedback
from trulens.feedback import GroundTruthAgreement
from trulens.providers.openai import OpenAI as fOpenAI
ground_truth_df = tru.get_ground_truth("test_dataset_new")
f_groundtruth = Feedback(
GroundTruthAgreement(ground_truth_df, provider=fOpenAI()).agreement_measure,
name="Ground Truth Semantic Similarity",
).on_input_output()
See this in action in the new Ground Truth Persistence Quickstart
New Component Guides and TruLens Cookbook¶
On the top-level of TruLens docs, we previously had separated out Evaluation, Evaluation Benchmarks, Tracking and Guardrails. These are now combined to form the new Component Guides.
We also pulled in our extensive GitHub examples library directly into docs. This should make it easier for you to learn about all of the different ways to get started using TruLens. You can find these examples in the top-level navigation under "Cookbook".
Automatic Migration with Grit¶
To assist you in migrating your codebase to TruLens to v1.0, we've published a grit pattern. You can migrate your codebase online, or by using grit on the command line.
Read more detailed instructions in our migration guide
Be sure to audit its changes: we suggest ensuring you have a clean working tree beforehand.
Conclusion¶
Ready to get started with the v1 stable release of TruLens? Check out our migration guide, or just jump in to the quickstart!