Debugging evaluation results with TruLens Hotspots¶
This notebook is a companion notebook to a general notebook showcasing TruLens using the Summeval benchmark. It can be run as a follow-up, but we will just copy all the relevant code from that notebook.
![]()
import os
os.environ["TRULENS_OTEL_TRACING"] = "0"
import os
os.environ["OPENAI_API_KEY"] = "sk-..."
os.environ["HUGGINGFACE_API_KEY"] = "hf_..."
import pandas as pd
file_path_dev = "dialogsum.dev.jsonl"
dev_df = pd.read_json(path_or_buf=file_path_dev, lines=True)
from trulens.apps.app import TruApp
from trulens.apps.app import instrument
import openai
class DialogSummaryApp:
def __init__(self):
self.client = openai.OpenAI()
@instrument
def summarize(self, dialog):
summary = (
self.client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": """Summarize the given dialog into 1-2 sentences based on the following criteria:
1. Convey only the most salient information;
2. Be brief;
3. Preserve important named entities within the conversation;
4. Be written from an observer perspective;
5. Be written in formal language. """,
},
{"role": "user", "content": dialog},
],
)
.choices[0]
.message.content
)
return summary
from trulens.core import TruSession
from trulens.dashboard import run_dashboard
session = TruSession()
session.reset_database()
# If you have a database you can connect to, use a URL. For example:
# session = TruSession(database_url="postgresql://hostname/database?user=username&password=password")
run_dashboard(session, force=True)
from trulens.core import Feedback
from trulens.feedback import GroundTruthAgreement
golden_set = (
dev_df[["dialogue", "summary"]]
.rename(columns={"dialogue": "query", "summary": "response"})
.to_dict("records")
)
from trulens.core import Select
from trulens.providers.huggingface import Huggingface
from trulens.providers.openai import OpenAI
provider = OpenAI(model_engine="gpt-4o")
hug_provider = Huggingface()
ground_truth_collection = GroundTruthAgreement(golden_set, provider=provider)
f_groundtruth = Feedback(
ground_truth_collection.agreement_measure, name="Similarity (LLM)"
).on_input_output()
# let's focus on Comprehensiveness
f_rouge = Feedback(ground_truth_collection.rouge).on_input_output()
f_comprehensiveness = (
Feedback(
provider.comprehensiveness_with_cot_reasons, name="Comprehensiveness"
)
.on(Select.RecordInput)
.on(Select.RecordOutput)
)
app = DialogSummaryApp()
tru_recorder = TruApp(
app,
app_name="Summarize",
app_version="v1",
feedbacks=[
f_groundtruth,
f_comprehensiveness,
f_rouge,
],
)
from tenacity import retry
from tenacity import stop_after_attempt
from tenacity import wait_random_exponential
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
def run_with_backoff(doc):
return tru_recorder.with_record(app.summarize, dialog=doc)
for i, pair in enumerate(golden_set):
llm_response = run_with_backoff(pair["query"])
if i % 25 == 0:
print(f"{i+1} {llm_response[0][:30]}...")
Time for hotspots!¶
You need to wait a little bit to check whether all evaluations have been done. Be patient, it might take a couple of minutes. You can check that in the TruLens dashboard (see the link at the beginning of the output for the previous cell).
When all or most evaluations are done (some might be missing, no problem), you can run Hotspots:
# !pip install trulens-hotspots
from trulens.hotspots.tru_hotspots import get_hotspots
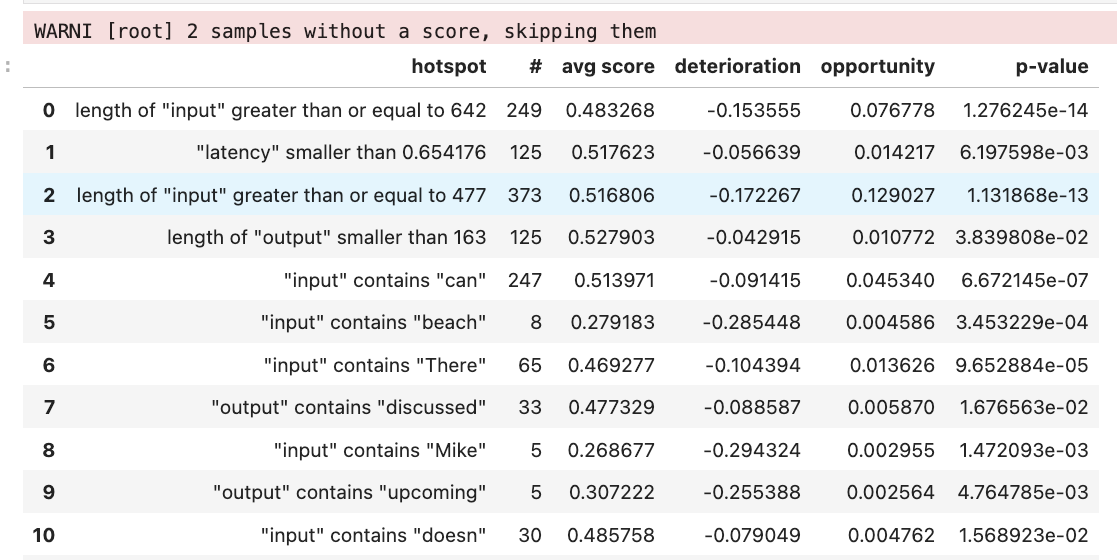
hotspots_df = get_hotspots(session, feedback="Comprehensiveness")
hotspots_df
(If you see a warning about >200 samples without a score, please wait more and re-run the above cell.)
The exact table will depend on your particular run, for this particular one (see screenshot below), it turned out that, perhaps unsurprisingly, long inputs are a challange. The comprehensive score is 17 pp. worse than for short inputs. Short and long outputs are problematic as well. Another interesting observation is that, for instance, inputs with "can" and "There" are unusually hard when you try to generate a comprehensive summary. If we somehow fixed the problem, we would get, respectively, +4 pp and +1 pp in the overall score.